
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- JanusGateway
- table not found
- Spring Batch
- k8s #kubernetes #쿠버네티스
- 달인막창
- vfr video
- 코루틴 빌더
- PytestPluginManager
- preemption #
- 티스토리챌린지
- PersistenceContext
- terminal
- 깡돼후
- 코루틴 컨텍스트
- 개성국밥
- mp4fpsmod
- 겨울 부산
- taint
- kotlin
- Value too long for column
- pytest
- 오블완
- python
- VARCHAR (1)
- JanusWebRTCGateway
- JanusWebRTC
- 자원부족
- tolerated
- JanusWebRTCServer
- 헥사고날아키텍처 #육각형아키텍처 #유스케이스
너와 나의 스토리
앙상블(Ensemble) / Random Forest 본문
- 앙상블: 일련의 예측기(분류나 회귀 모델)
- 앙상블 학습(Ensemble learning): 일련의 예측기로부터 예측을 수집하면 가장 좋은 모델 하나보다 더 좋은 예측을 얻을 수 있을 것
- 앙상블 방법(Ensemble method): 앙상블 학습 알고리즘
훈련 세트로부터 무작위로 각기 다른 서브셋을 만들어 일련의 결정 트리 분류기를 훈련시킬 수 있다. 예측을 하려면 모든 개별 트리의 예측을 구하면 된다. 그런 다음 가장 많은 선택을 받은 클래스를 예측으로 삼는다.
- 랜덤 포레스트(Random forest): 결정 트리의 앙상블
- 가장 강력한 머신러닝 알고리즘
- Ensemble method - 배깅, 부스팅, 스태킹 등
1. 투표 기반 분류기
좋은 분류기를 만드는 방법은 (로지스트)회귀 분류기, SVM 분류기, 랜덤 포레스트 분류기, K-최근접 이웃 분류기 등 여러 분류기의 예측을 모아서 가장 많이 선택된 클래스를 예측하는 것이다. 이렇게 다수결 투표로 정해지는 분류기를 직접 투표(hard voting) 분류기라고 한다.

log_clf = LogisticRegression(solver='liblinear')
rnd_clf = RandomForestClassifier(n_estimators=10)
svm_clf = SVC(gamma='auto')
voting_clf = VotingClassifier(estimators=[('lr',log_clf),('rf',rnd_clf),('svc',svm_clf)], voting='hard')각 분류기가 약한 학습기(weak learner)일지라도 충분하게 많고 다양하다면 앙상블은 강한 학습기(strong learner)가 될 수 있습니다. -> 큰 수의 법칙(law of large numbers) 때문에
앙상블 방법의 예측기가 가능한 한 서로 독립적일 때 최고의 성능을 발휘한다. 다양한 분류기를 얻는 한 가지 방법은 각기 다른 알고리즘으로 학습시키는 것이다. 이렇게 하면 매우 다른 종류의 오차를 만들 가능성이 높기 때문에 앙상블 모델의 정확도를 향상시킨다.
모든 분류기가 클래스의 확률을 예측할 수 있으면, 개별 분류기의 예측을 평균 내어 확률이 가장 높은 클래스를 예측할 수 있다. 이를 간접 투표(soft voting)라고 한다.
hard voting은 잘못된 클래스가 다수인 경우 앙상블의 정확도가 낮아지지만, soft voting은 확률이 높은 투표에 비중을 더 두기 때문에 hard voting보다 성능이 더 좋다.
hard voting 사용하려면 voting="soft"로 바꾸고 모든 분류기가 클래스의 확률을 추정할 수 있으면 된다.
2. 배깅과 페이스팅
같은 알고리즘을 사용하지만 훈련 세트의 서브셋을 무작위로 구성하여 분류기를 각기 다르게 학습시킴
- 배깅(bagging): (bootstrap aggregating의 줄임말)훈련 세트에서 중복을 허용하여 샘플링하는 방식
- 페이스팅(pasting): 중복을 허용하지 않고 샘플링하는 방식
- 즉, 배깅과 페이스팅은 같은 훈련 샘플을 여러 개의 예측기에 걸쳐 사용할 수 있다
- 모든 예측기가 훈련을 마치면 앙상블은 모든 예측기의 예측을 모아서 새로운 샘플에 대한 예측을 만든다. 수집 함수는 전형적으로 분류일 때는 통계적 최빈값(statistical mode; 직접 투표 분류기처럼 가장 많은 예측 결과)이고 회귀에 대해서는 평균을 계산한다.
- 개별 예측기는 원본 훈련 세트로 훈련시킨 것보다 훨씬 크게 편향되어 있지만 수집 함수를 통과하면 편향과 준산이 모두 감소한다.
- oob 평가
- oob(out-of-bag) 샘플: 선택되지 않은 훈련 샘플의 나머지 37%
- 앙상블 평가: 각 예측기의 oob 평가를 평균하여 얻음
- 사이킷런에서 BaggingClassifier를 만들 때 oob_score = True로 지정하면 훈련이 끝난 후 자동으로 oob 평가
3. 랜덤 패치와 랜덤 서브스페이스
- 각 예측기는 무작위로 선택한 입력 특성의 일부분으로 훈련된다.
- 특히 고차원의 데이터셋을 다룰 때 유용하다
- 랜덤 패치 방식(Random Patches method): 훈련 특성과 샘플을 모두 샘플링하는 것
- 랜덤 서브스페이스 방식(Random Subspaces method): 훈련 샘플을 모두 사용하고 특성은 샘플링하는 것
- 특성 샘플링은 더 다양한 예측기를 만들며 편향을 늘리는 대신 분산을 낮춘다.
4. 랜덤 포레스트
- 랜덤 포레스트: 일반적으로 배깅 방법(또는 페이스팅)을 적용한 결정 트리의 앙상블
- 랜덤 포레스트 알고리즘 트리의 노드를 분할할 때 전체 특성 중에서 최선의 특성을 찾는 대신 무작위로 선택한 특성 후보 중에서 최적의 특성을 찾는 식으로 무작위성을 더 주입한다.
- 이는 결국 트리를 더욱 다양하게 만들고 편향을 손해 보는 대신 분산을 낮추어 전체적으로 더 훌륭한 모델을 만들어낸다.
- 랜덤성에 의해 트리들이 서로 조금씩 다른 특성을 갖는다
- 이 특성은 각 트리들의 예측들이 비상관화(decorrelation) 되게하며, 결과적으로 일반화(generalization) 성능을 향상시킨다.
- 또한, 랜덤화(randomization)는 포레스트가 노이즈가 포함된 데이터에 대해서도 강인하게 만들어 준다.
- 랜덤화는 각 트리들의 훈련 과정에서 진행되며, 램덤 학습 데이터 추출 방법을 이용한 앙상블 학습법인 배깅(baggain)과 랜덤 노드 최적화(randomized node optimization)가 자주 사용된다.
- 엑스트라 트리
- 트리를 더욱 무작위하게 만들기 위해 최적의 임곗값을 찾는 대신 후보 특성을 사용해 무작위로 분할한 다음 그중에서 최상의 분할을 선택한다.
- 익스트림 랜덤 트리(Extremely Randomized Trees): 이와 같이 극단적으로 무작위한 트리의 랜덤 포레스트
- 줄여서 엑스트라 트리(Extra-Trees)라고 부름
- 편향이 늘어나지만 분산이 낮아짐
- 모든 노드에서 특성마다 가장 최적의 임곗값을 찾는 것이 트리 알고리즘에서 가장 시간이 많이 소요되는 작업 중 하나이므로 일반적인 랜덤 포레스트보다 엑스트라 트리가 훨씬 빠르다
- 특성 중요도
- 랜덤 포레스트는 특성의 상대적 중요도를 측정하기 쉽다.
- 사이킷런은 어떤 특성을 사용한 노드가( 랜덤 포레스트에 있는 모든 트리에 걸쳐서) 평균적으로 불순도를 얼마나 감소시키는지 확인하여 특성의 중요도를 측정한다.
- 즉, 가중치 평균이며 각 노드의 가중치는 연관된 훈련 샘플 수와 같다
- 사이킷런은 훈련이 끝난 뒤 특성마다 자동으로 이 점수를 계산하고 중요도의 전체 합이 1이 되도록 결괏값을 정규화한다.
5. 부스팅
- 부스팅(boosting): 약한 학습기를 여러 개 연결하여 강한 학습기를 만드는 앙상블 방법
- 아이디어: 앞의 모델을 보완해나가면서 일련의 예측기를 학습시키는 것
- 부스팅 방법 - 아다부스트(AdaBoost), 그래디언트 부스팅(Gradient Boosting)
아다부스트
- 이전 모델이 과소적합했던 훈련 샘플의 가중치를 더 높여서 이전 예측기를 보완하여 새로운 예측기 만듦
- 이러한 연속된 학습 기법은 경사 하강법과 비슷한 면이 있다. 경사 하강법은 비용 함수를 최소화하기 위해 한 예측기의 모델 파라미터를 조정하지만 아다부스트는 점차 더 좋아지도록 앙상블에 예측기를 추가한다.
n: 학습률 하이퍼파라미터
예측기가 정확할수록 가중치가 더 높아지게 된다.
만약 무작위로 에측하는 정도이면 가중치는 0에 가깝고, 그 보다 정확도가 낮으면 가중치는 음수가 된다.
그 다음에 [식 7-3]을 사용해 샘플의 가중치를 업데이트한다. 즉, 잘못 분류된 샘플의 가중치가 증가된다.
그 후, 모든 샘플의 가중치를 정규화한다 (즉, $\sum_{i=1}^{m}w_{i}$으로 나눈다)
마지막으로 새 예측기가 업데이트된 가중치를 사용해 훈련되고 전체 과정이 반복된다.
예측을 할 때, 아다부스트는 단순히 모든 예측기의 예측을 계산하고 예측기 가중치 $a_{j}$를 더해서 예측 결과를 만든다. 가중치 합이 가장 큰 클래스가 예측 결과가 된다.
그래디언트 부스팅
- 앙상블에 이전까지의 오차를 보정하도록 예측기를 순차적으로 추가한다.
- 하지만 아다부스트처럼 반복마다 샘플의 가중치를 수정하는 대신 이전 예측기가 만든 잔여 오차(residual error)에 새로운 예측기를 학습시킨다.
- Gradient Tree Boosting 또는 Gradient Boosted Regression Tree(GBRT): 결정 트리를 기반 예측기로 사용하는 회귀 문제
- learning rate를 낮게 설정하면 앙상블을 훈련 세트에 학습시키기 위해 많은 트리가 필요하지만 일반적으로 예측의 성능은 좋아진다. -> 이는 축소(shrinkage)라고 부르는 규제 방법이다
- GradientBoostingRegressor는 각 트리가 훈련할 때 사용할 훈련 샘플의 비율을 지정할 수 있는 subsample 매개변수도 지원한다. 예를 들어 subsample=0.25라고 하면 각 트리는 무작위로 선택된 25%의 훈련 샘플로 학습된다. 이렇게 하면 편향이 높아지는 대신 분산이 낮아지게 된고 훈련 속도가 상당히 높다. -> 이를 확률적 그래디언트 부스팅(Stochastic Gradient Boosting)이라고 한다.
6. 스태킹
- 스태킹(stacking) - stacked generalization의 줄임말
- 기본 아이디어: 앙상블에 속한 모든 예측기의 예측을 취합하는 간단한 함수(직접 투표 같은)를 사용하는 대신 취합하는 모델을 훈련시킬 수는 없을까?
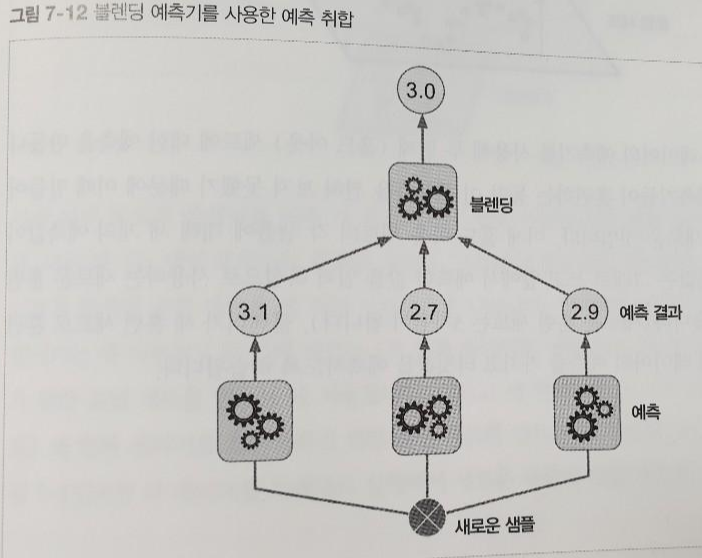
- [그림 7-12] 세 예측기가 각각 다른 값을 예측하고 마지막 예측기(blender 또는 meta learner라고 함)가 이 예측을 입력으로 받아 최종 예측을 만든다.
- 블랜더를 학습시키는 일반적인 방법은 홀드 아웃(hold-out)세트를 사용하는 것이다.
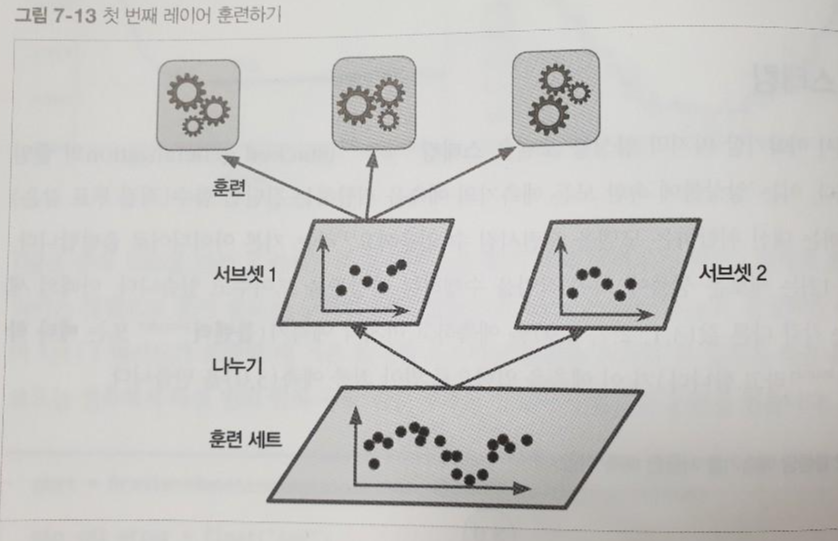
- [그림 7-13]을 보면, 먼저 훈련 세트를 두 개의 서브셋으로 나눈다. 첫 번째 서브셋은 첫번째 레이어의 예측을 훈련시키기 위해 사용된다.
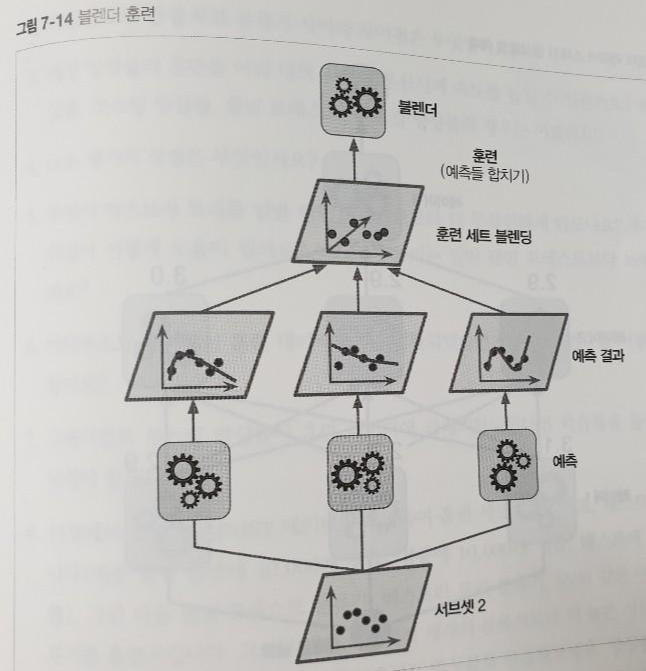
- 그런 다음, 첫 번째 레이어 예측기를 사용해 두 번째 (홀드 아웃) 세트에 대한 예측을 만든다 [그림 7-14]
- 이제 홀드 아웃 세트의 각 샘플에 대해 세 개의 예측값이 만들어진다. 타깃값은 그대로 쓰고 앞에서 예측한 값을 입력 특성으로 사용하는 새로운 훈련 세트를 만들 수 있다 (새로운 훈련 세트는 3차원이 된다)
- 블렌더가 새 훈련 세트로 훈련된다. 즉, 첫 번째 레이어의 예측을 가지고 타깃값을 예측하도록 학습된다.
- 블렌더 여러 개 훈련 시키는 것도 가능 -> 블렌더만의 레이블이 만들어진다
출처: Hands-On machine learning with Scikit-Learn & TensorFlow
'Data Analysis > Machine learning' 카테고리의 다른 글
| [ML] Nonparametric vs Parametric statistics (0) | 2019.08.19 |
|---|---|
| Incremental decision tree (0) | 2019.08.18 |
| [ML] Decision Tree - classification / regression (0) | 2019.08.15 |
| Training - BPTT / RTRL / EKF (0) | 2019.08.13 |
| SGD / EKF / PF algorithm (0) | 2019.08.12 |

