
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- JanusWebRTCServer
- PersistenceContext
- preemption #
- 달인막창
- taint
- python
- 겨울 부산
- 오블완
- Spring Batch
- 티스토리챌린지
- PytestPluginManager
- 헥사고날아키텍처 #육각형아키텍처 #유스케이스
- vfr video
- JanusWebRTCGateway
- tolerated
- k8s #kubernetes #쿠버네티스
- JanusGateway
- VARCHAR (1)
- 자원부족
- Value too long for column
- 개성국밥
- 깡돼후
- terminal
- JanusWebRTC
- mp4fpsmod
- kotlin
- 코루틴 컨텍스트
- table not found
- pytest
- 코루틴 빌더
너와 나의 스토리
[CH.3] Connection-oriented transport: TCP - segment structure, reliable data transfer, flow control, connection management / congestion control /TCP congestion control 본문
[CH.3] Connection-oriented transport: TCP - segment structure, reliable data transfer, flow control, connection management / congestion control /TCP congestion control
노는게제일좋아! 2019. 10. 11. 03:22TCP
- point-to-point:
- 한 명의 송신자, 한 명의 수신자
- multicasting 불가
- tcp는 오로지 end system에서만 동작
- 중간에 라우터나 브리지에서 동작하지 않는다
- reliable, in-order byte stream:
- 메시지 경계가 없다 => 패킷 트레인 이용
- pipelined:
- TCP congestion과 flow control에서 window 사이즈를 설정한다.
- full duplex data
- 같은 연결에서 bi-directional data flow
- 보내는 것과 받는 것이 동시에 가능
- A->B로 보내면 B->A로 보낼 수 있음
- MSS: 최대 세그먼트 크기
- 세그먼트의 데이터 필드의 크기 제한
- 사이즈 큰 파일 전송할 때, MSS 크기로 파일 자른다.
- 같은 연결에서 bi-directional data flow
- connection-oriented:
- '3 way handshaking'을 통해 데이터 교환 전에 송수신자의 상태를 초기화한다.
- TCP를 연결 지향이라고 부르는 이유
- '3 way handshaking'을 통해 데이터 교환 전에 송수신자의 상태를 초기화한다.
- flow controlled:
- 송신자는 수신자가 받을 수 있을 만큼만 보낸다.
TCP segment structure

- source, dest port: 다중화/역다중화에 사용
- seq num: 순서 번호 필드
- acknowledgement num: 확인 응답 번호 필드
- receive window: flow control 할 때, 사용
TCP seq. number, ACKs
- seq. number
- 데이터 스트림이 500,000byte이고, MSS가 1000이면 500개의 세그먼트가 생긴다. 첫 번째 세그먼트의 순서번호(sequence number)는 0, 두 번째 세그먼트의 순서 번호는 1000이 된다.
- ACKs
- 수신자가 0~535 바이트를 포함하는 세그먼트와, 900~1000 바이트를 포함하는 세그먼트를 수신했다고 하자.
- 수신자는 아직 536~899 바이트를 수신하지 않았다.
- 그럼 수신자는 데이터 스트림을 재생성하기 위해 536번째 바이트를 기다리고 있으므로 다음 세그먼트 확인 응답 번호 필드(acknowledgement num)를 536으로 지정한다. (원하는 바이트+1)
- cummulative ACK (원하는 바이트+1)
- 예:
- Host A는 seq num이 42, Host B는 seq num이 79라고 하자

host A는 42번째 바이트를 보내면서, 79번째 바이트를 host B에게 요구한다.
host B는 79번째 바이트를 보내면서, 다음 원하는 바이트인 43 바이트를 A에게 요구한다. (축적된 ack)
TCP round trip time, timeout
- 어떻게 TCP timeout 값을 정할까?
- RTT 보다는 길어야 한다.
- 너무 짧으면: premature한 timeout이 된다. -> 불필요한 재전송 유발
- 너무 길면: 세그먼트 loss에 대한 반응이 너무 느림
- 어떻게 RTT를 추정할까?
- SampleRTT: 세그먼트 전송부터 ACK 응답이 올 때까지 걸린 시간 측정
- 재전송은 무시
- 1번 측정하고 바로 SampleRTT로 정하는 게 아니라 최근 몇 번 측정한 것의 평균을 이용
- SampleRTT: 세그먼트 전송부터 ACK 응답이 올 때까지 걸린 시간 측정


TCP: Reliable data transfer
- TCP는 IP의 비신뢰적인 서비스 위에서 rdt 서비스를 제공한다.
- pipelined segments
- cumulative acks
- single retransmission timer
- 재전송은 다음으로 인해 발생한다
- timeout 발생
- 중복된 ack
TCP sender events
- application layer로부터 데이터를 받음
- seq num을 가지는 세그먼트를 만듦
- seq num은 세그먼트에서 첫 데이터의 바이트의 바이트 스트림 수이다.
- 만약 타이머가이미다른세그먼트에대해서실행중이아니라면
- unacked 세그먼트에서 가장 오래된 것에 대한 타이머 시작
- tcp는 이 세그먼트를 IP로 넘길 때 타이머를 시작 -> 그니까 가장 오래된 것
- 타이머 만료 주기: TimeOutInterval
- unacked 세그먼트에서 가장 오래된 것에 대한 타이머 시작
- timeout:
- timeout으로 인한 세그먼트 재전송
- 타이머 재시작
- ack 받음:
- 만약 unacked 세그먼트에 대한 ack을 받은 거라면
- ack 된 거 업데이트
- 현재 ack 들어온 게 원래 가장 오래된 unacked 세그먼트였다면 timer 재시작
- 만약 unacked 세그먼트에 대한 ack을 받은 거라면

다음을 무시하고 간단하게 만든 것
- 중복된 ack
- flow control
- congestion control
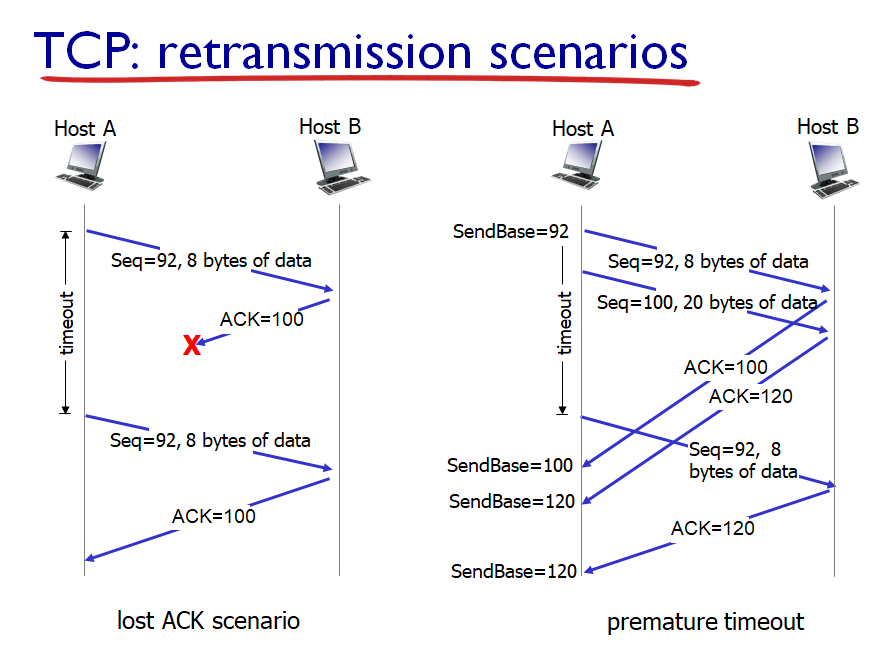
host B가 seq 92인 데이터를 8 바이트 받았다면 ack은 (92+8)인 100을 보낸다
=> cummulative ack

ack=100이 제대로 안 갔어도
ack=120이 제대로 가면, 그 전 것들은 다 제대로 갔다고 host A는 생각
TCP ACK 발생
| event | TCP 수신자 action |
| 기다리는 순서 번호를 가진 '순서가 맞는' 세그먼트의 도착. 기다리는 순서 번호까지의 모든 데이터들은 이미 확인 응답됨. | [delayed ACK] 또 다른 '순서가 맞는' 세그먼트의 도착을 위해 500 msec까지 기다린다. 만약 다음 '순서에 맞는' 세그먼트가 이 기간에 도착하지 않으면, ACK을 보낸다. |
| 기다리는 순서번호를 가진 '순서가 맞는' 세그먼트의 도착. ACK 전송을 기다리는 다른 하나의 '순서에 맞는' 세그먼트 있음 | [cumulative ACK] 즉시 2개의 '순서가 맞는' 세그먼트들을 ACK 하기 위해, 하나의 누적된 ACK을 보낸다(최근 것). |
| 기다리는 것보다 높은 순서번호를 가진 '순서가 틀린' 세그먼트의 도착. | [duplicate ACK]즉시 순서번호가 다음의 기다리는 바이트(원래 받아야 하는 번호)를 나타내는 중복 ACK를 보낸다. |
| 수신 데이터에서 격차를 부분적으로 또는 모두 채우는 세그먼트의 도착 | [immediate send ACK]즉시 ACK를 보낸다. 단, 그 세그먼트가 격차의 최솟값에서 시작한다고 가정. |
TCP fast retransmit
- time out 기다리는 거 너무 오래 걸려요~
- 손실된 패킷을 재전송하기 전 delay가 길다
- 중복된 ACK를 통한 손실 세그먼트 탐지
- 송신자는 종종 많은 세그먼트를 back-to-back으로 보낸다
- 세그먼트가 손실되면 많은 중복된 ack들을 받게 될 것이다.
- TCP fast retransmit
- 똑같은 세그먼트에 대해 ACK이 3번 들어왔다면, 그다음 세그먼트가 손실되었다는 것을 의미한다.
- 이 경우, 타이머를 기다리는 것이 아니라, 바로 unACKed 세그먼트(가장 작은 seq num)를 재전송한다.

TCP: flow control
- 애플리케이션이 읽는 속도와 송신자가 전송하는 속도를 같게한다.
- TCP는 전이중이므로 각 측의 송신자는 별개의 수신 윈도우를 유지한다.

수신자의 receiver buffer가 넘치지 않도록 송신자가 데이터를 송신하도록 송신자에게 receiver buffer를 알려준다

송수신자 세그먼트의 TCP 헤더에 있는 rwnd 값을 포함함으로써 수신자는 free buffer space를 알린다.
rwnd: 수신자의 unacked data를 저장하는 최대 양
수신자 버퍼가 오버플로우되지 않는 것을 보장
TCP: Connection Management
- 데이터를 교환하기 전, 송수신자들은 "handshake"를 한다
- 연결 동의
- 연결 파라미트 동의
- TCP 3-way handshake

- 클라이언트가 서버한테 SYN을 보냄
- 서버가 클라이언트한테, 아까 받은 SYN에 대한 SYN와 ACK을 보냄
- 클라이언트가 서버한테 ACK 보냄

TCP: closing a connection
- 클라이언트와 서버 각 각 연결을 끊는다.
- FIN bit =1과 함께 TCP 세그먼트를 보내서
- 받은 FIN에 대해 ACK을 보낸다
- 동시에 FIN 교환 가능

둘 다 끝내자고 FIN을 보내야 하고
그에 대한 대답(ACK)도 각각 보내야 함
이렇게 연결 끊을 때도, 연결(대화) 다 하고 끊기 때문에 connection-oriented라고도 할 수 있다.
Principles of congestion control
* flow control과 congestion control 차이
- flow control: 송신측과 수신측의 데이터 처리 속도 차이를 해결하기 위한 기법
- congestion control: 송신측의 데이터 전달과 네트워크의 데이터 처리 속도 차이를 해결하기 위한 기법
congestion
- 네트워크가 처리하기에는 너무 많은 데이터를 너무 빨리 보내는 자원이 너무 많다.
- 라우터에서 버퍼 오버플로우가 발생해서 -> 패킷 손실
- 라우터 버퍼에서 queueing 때문에 -> delay가 길어짐
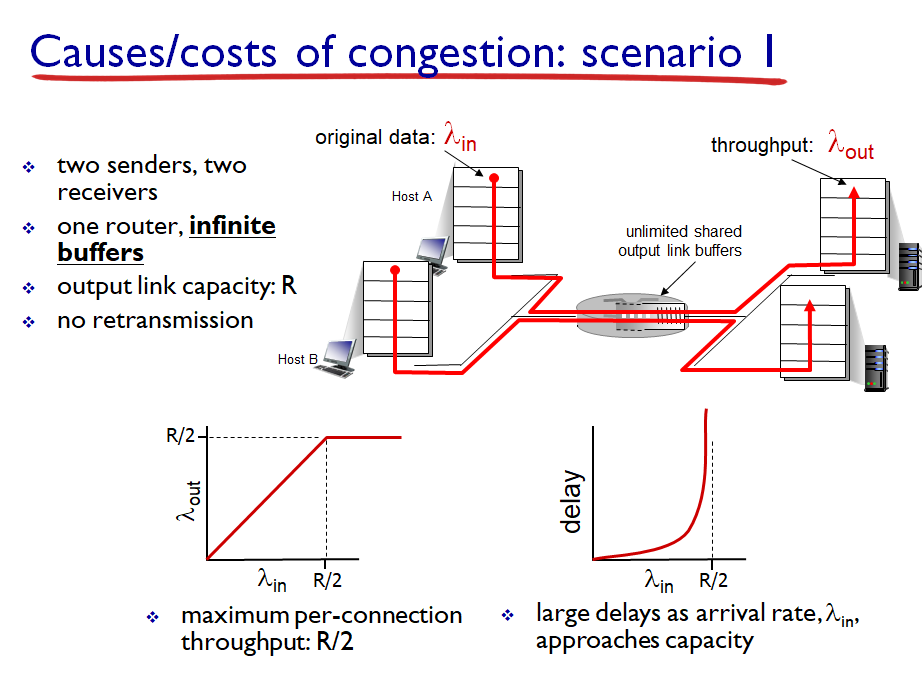
두 개의 호스트가 하나의 라우터 사용하므로 라우터 capacity (R)을 반 나눠서 사용

버퍼가 유한하기 때문에
버퍼가 다 찼는데, 들어오는 패킷들은 버려진다.

가정2: 호스트 A가 라우터에 있는 버퍼가 비어 있는지 아닌지 안다고 해보자.
->송신자는 버퍼가 비어 있을 때만 송신
-> 패킷 손실이 일어나지 않음
=> 시나리오1과 유사
가정3: 패킷 손실된 것을 알았을 때만 송신자가 재전송을 한다고 하자.
=> 총 R/2의 데이터를 전송했을 때, 원본 데이터는 R/3밖에 전송되지 않는다.

가정4: 송신자에서 너무 일찍 타임아웃되는 바람에 패킷이 손실되지 않았지만 큐에서 지연되고 있는 패킷을 재전송하는 경우
-> 수신자는 중복되서 받은 패킷 버림
-> 수신자가 이미 받았는데 수신자가 똑같은거 포워딩 하고 있는 작업은 낭비
=> 총 R/2의 데이터를 전송했을 때, 원본 데이터는 R/4밖에 전송되지 않는다.

B->D랑 A->C랑 R2를 같이 씀
B->D 처리량으로 R2가 꽉차면 A->C 처리량은 0이 되고 R2로 보내지는 패킷들은 버려진다.
R1은 이 와중에 R2에게 열심히 (A->C)데이터를 보냈는데 다 헛된 짓이였다.
이 시간에 R1에서 사용되는 전송 용량을 다른 패킷을 전송하는데 썼으면 더 유용했을텐데..
congestion control에 대한 접근
- end-end congestion control
- 네트워크로부터 어떠한 피드백도 받지 않고
- 손실이나 지연 등을 end system이 추측하는 방법
- TCP에서 사용
- Network-assisted congestion control
- 라우터가 혼잡 상태에 관한 정보를 수신자에게 직접 전달하는 방식
- SNA, ATM, DECbit 등에서 사용
TCP congestion control
- 접근: 네트워크 혼잡에 따라 연결에 트래픽을 보내는 전송률을 각 송신자가 제한하도록 하는 것이다.
- additive increase: loss가 발생하기 전까지 모든 RTT마다 cwnd를 1 MSS씩 증가시킨다.
- multiplicative decrease: loss가 발생하면 cwnd를 절반으로 줄인다.
- cwnd(congestion window): TCP 송신자가 네트워크로 트래픽을 전송할 수 있는 비율을 제한

- 송신자의 전송 제한: (LastByteSent-LastByteAcked) ≤ cwnd
- cwnd: 네트워크 혼잡에 따라 유동적이다.
- TCP 전송 속도: (cwnd/RTT) bytes/sec
loss 발생
- timeout
- cwnd는 1 MSS로 설정됨
- threshold까지는 exponential하게 증가하다가, 그 후부터는 linearly하게 증가
- 3개의 중복된 ACK 들어옴
- cwnd는 절반이 되고, linearly하게 증가
- TCP Tahoe는 항상 cwnd가 1로 설정됨 (loss 발생하면)
TCP: switching from slow start to CA

처음에는 cwnd가 1
ssthresh(임계점)까지는 지수적으로 증가하다가 그 후부터는 1씩 증가
8초에서 loss가 발생
임계점은 loss 발생할 때 cwnd의 절반으로 설정됨
TCP Tahoe는 1로 떨어지고 TCP Reno는 임계점부터 시작
TCP Tahoe와 TCP Reno가 분리되었다는 것은 3 duplication ACK이 발생되었음을 의미한다.

출처: [Computer networking: A top-down approach, 6th]
'Computer Networks > 이론' 카테고리의 다른 글
| [CH.4] Network Layer - 라우터 내부 (0) | 2019.11.14 |
|---|---|
| [CH.4] Network Layer - virtual circuit(VC) vs datagram networks (0) | 2019.10.15 |
| [CH.3] Transport Layer - multiplexing/demultiplexing, Connectionless transport: UDP, principles of reliable data transfer (0) | 2019.10.07 |
| [CH.2] Socket programming with UDP and TCP (0) | 2019.10.04 |
| [CH.2] Application Layer - P2P applications (2) | 2019.10.04 |



