
Recent Posts
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- VARCHAR (1)
- 겨울 부산
- 깡돼후
- PytestPluginManager
- tolerated
- Value too long for column
- terminal
- taint
- preemption #
- pytest
- JanusGateway
- mp4fpsmod
- 자원부족
- PersistenceContext
- vfr video
- JanusWebRTC
- Spring Batch
- 코루틴 컨텍스트
- JanusWebRTCServer
- 개성국밥
- table not found
- JanusWebRTCGateway
- python
- 헥사고날아키텍처 #육각형아키텍처 #유스케이스
- 오블완
- k8s #kubernetes #쿠버네티스
- 달인막창
- 티스토리챌린지
- 코루틴 빌더
- kotlin
Archives
너와 나의 스토리
[ML] Random Forest Regression 본문
반응형
Ensemble learning
- 참조
- Ensemble method: 여러개의 머신 러닝 알고리즘으로부터 예측을 결합하는 기술
Types of Ensemble Learning (model combining method)
- Boosting
- AdaBoost / Gradient Boost
- Bosststrap Aggregation (Bagging)
- Majority Voting / Bagging / Random forest
- Boosting
- 가중치 평균을 사용하여 약한 학습자를 더 강력한 학습자로 만드는 알고리즘 그룹을 말한다.
- "teamwork"에 관한 것
- 실행되는 각 모델은 다음 모델에 집중할 feature을 결정한다
- 차례대로 하나는 다른 것으로부터 배우고, learning을 boosting함
- Bootstrap Aggregation (Bagging)
- 교체된 random sampling을 말한다.
- 부트스트랩을 사용하면 데이터 세트의 bias(편향)와 variance(분산)을 더 잘 이해할 수 있다
- 데이터 세트에서 작은 데이터 하위 집합을 random sampling한다
- decision tree처럼 분산이 높은 알고리즘의 분산을 줄이는데 사용할 수 있는 일반적인 절차이다.
- Bagging은 각 모델을 독립적으로 실행한 다음 어떤 모델을 선호하지 않고 마지막에 출력을 집계한다.
- Majority Voting(다수결)
- 가장 단순한 모델 결합 방법으로 전혀 다른 모형도 결합할 수 있다. 다수결 방법은 Hard Voting과 Soft Voting 두 가지로 나뉘어진다.
- Hard voting: 단순 투표, 개별 모형의 결과 기준
- Soft voting: 가중치 투표, 개별 모형의 조건부 확률의 합 기준
- Scikit-Learn의 ensemble 서브패키지는 다수결 방법을 위한 VotingClassifier 클래스를 제공한다.
- estimators: 개별 모형 목록, 리스트나 named parameter 형식으로 입력
- voting: 문자열{hard, soft} hard voting인지 soft voting인지 선택 ( 디폴트로는 hard)
- weight: 사용자 가중치 리스트
- Bagging(배깅)
- 동일한 모형과 모형 모수를 사용하는 대신 부트스트래핑(bootstrapping)과 유사하게 트레이닝 데이터를 랜덤하게 선택해서 다수결 모형을 적용한다
- 트레이닝 데이터를 선택하는 방법에 따라 다음과 같이 부르기도 한다.
- Pasting: 같은 데이터 샘플을 중복사용(replacement)하지 않음
- Bagging: 같은 데이터 샘플을 중복사용(replacement)
- Random Subspaces: 데이터가 아니라 다차원 독립 변수 중 일부 차원을 선택하는 경우
- Random Patches: 데이터 샘플과 독립 변수 차원 모두 일부만 랜덤하게 사용
- 성능 평가시에는 트레이닝용으로 선택한 데이터가 아닌 다른 데이터를 사용할 수도 있다. 이런 데이터를 OOB(out-of-bag) 데이터라고 한다.
Problems with Decision Tree
- Decision tree는 훈련된 특정 데이트에 민감해서 훈련 데이터가 변경되면 decision tree의 결과(예측)는 상당히 달라질 수 있다.
- 훈련시키는데 computationally expensive하고 overfitting 위험이 있고, local optima를 찾는 경향이 있다(쪼개진 후 그 전으로 돌아갈 수 없어서)
Random Forest
- classification과 regression을 위한 ensemble learning method를 사용하는 Supervised Learning algorithm이다.
- bagging 테크닉이다 (not a boosting technique)
- random forest의 tree들은 평행하게 작동된다. 이 트리를 생성할 때 트리들끼리 상호 작용하지 않는다
- 훈련 시간에 다수의 decision tree를 구성하고 개별 트리의 클래스 모드(classification) 또는 평균 예측(regression)인 클래스를 출력하여 작동한다
- random forest는 몇 가지 유용한 수정 사항과 함께 많은 decision trees를 집계하는 meta-estimator이다 (즉, 여러개의 예측을 결합함)
- 각 노드에서 쪼개질 수 있는 feature의 수는 전체(hyperparameter) 일부 비율로 제한된다. Ensemble model은 개별 feature에 크게 의존하지 않고 잠재적으로 예측 가능한 모든 feature을 공정하게 사용할 수 있음을 보장한다
- 각 트리는 분할을 생성할 때 원래의 데이터 셋에서 랜덤 샘플을 가져와서 overfitting을 방지하는 랜덤 요소를 추가한다
위의 수정은 트리가 너무 높은 상관관계를 방지하는데 도움이된다.
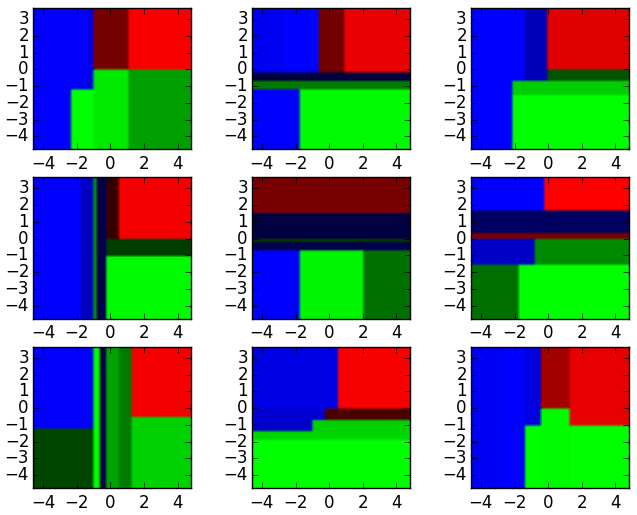
이러한 decision tree classifier는 입력을 결합한 random forest ensemble로 aggregate될 수 있다. 위의 의사 결정 트리 출력의 가로 및 세로 축을 x1, x2로 생각해보자. 각 feature의 특정 값들에서 의사 결정 트리는 "파란색", "녹색",
빨간색" 등의 분류를 출력한다
이러한 결과는 model votes 또는 averaging을 통해 개별 decision tree의 결과를 능가하는 단일 앙상블 모델로 집계된다.
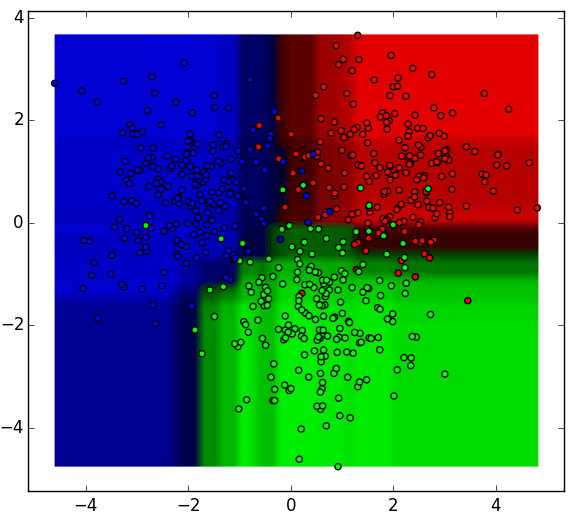
Random Forest의 장점과 특징
- 사용 가능한 가장 정확한 learning algorithm 중 하나
- 많은 데이터 세트의 경우 매우 정확한 분류기를 생성
- 큰 데이터베이스에서 효율적으로 실행됨
- 변수 삭제없이 수천개의 입력 변수를 처리할 수 있다
- 분류에 중요한 변수를 추정
- forest building이 진행됨에 따라 내부화되지 않은 일반화 오류 추정치를 생성한다
- 누락된 데이터를 추정하는 효과적인 방법을 가지고 있으며 많은 양의 데이터가 누락된 경우 정확도를 유지한다
Random Forest 단점
- noise classification/regression이 있는 일부 데이터 세트에 overfitting하는 것으로 관찰됨
- 레벨 수가 다른 범주형 변주를 포함한 데이터의 경우 랜덤 포레스트는 더 많은 레벨을 가진 속성에 유리하게 편향된다. 따라서 랜덤 포레스트의 변수 importance scores는 이 유형의 데이터에 대해 신뢰할 수 없다
출처:
데이터 사이언스 스쿨 - https://datascienceschool.net/view-notebook/766fe73c5c46424ca65329a9557d0918/
Towards Data Science - https://towardsdatascience.com/random-forest-and-its-implementation-71824ced454f
반응형
'Data Analysis > Machine learning' 카테고리의 다른 글
| [ML] 푸아송 분포(Poisson distribution) (0) | 2019.08.27 |
|---|---|
| Random forest regression 실습 1 (0) | 2019.08.19 |
| [ML] Expert system vs Machine learning (0) | 2019.08.19 |
| [ML] Nonparametric vs Parametric statistics (0) | 2019.08.19 |
| Incremental decision tree (0) | 2019.08.18 |
'Data Analysis/Machine learning' Related Articles
more

