
Recent Posts
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 헥사고날아키텍처 #육각형아키텍처 #유스케이스
- 오블완
- pytest
- 겨울 부산
- PytestPluginManager
- terminal
- 개성국밥
- PersistenceContext
- JanusWebRTCGateway
- 깡돼후
- 달인막창
- JanusWebRTCServer
- k8s #kubernetes #쿠버네티스
- VARCHAR (1)
- tolerated
- JanusGateway
- python
- JanusWebRTC
- 자원부족
- preemption #
- 티스토리챌린지
- table not found
- mp4fpsmod
- taint
- 코루틴 빌더
- 코루틴 컨텍스트
- Value too long for column
- Spring Batch
- kotlin
- vfr video
Archives
너와 나의 스토리
[Data Mining] Ch5. Alternative Classification 본문
반응형
Instance-Based Classifiers
- 모델을 안 만들고 분류하는 방법
- 미리 저장된 트레이닝 데이터 필요
- 트레이닝 데이터를 사용해서 label 없는 데이터의 클래스 예측
- Example:
- Rote-learner
- 트레이닝 데이터를 전부를 기억하고 새로운 데이터의 attribute 값이 트레이닝 셋에 속하는 데이터와 완전히 일치할 때, 클래스를 판단
- Nearest neighbor
- 새로운 데이터가 트레이닝 셋과 가장 근사한 것으로 클래스 분류
- Rote-learner
Nearest Neighbor Classifiers
- 기본 아이디어: 오리처럼 뒤뚱뒤뚱 걷고, 꽥꽥 소리 내면, 이것은 아마 오리일 것이다.

Nearest-Neighbor Classifiers
- 기존 트레이닝 셋에 있는 데이터와 현재 새로운 데이터와 유사도를 계산할 수 있는 similarity measure가 필요
- -> record들 사이의 distance 계산할 "Distance Matric"
- k를 정함 -> k: 가장 가까운 애들 k개를 본다

- (a): -로 판단
- (b): 판단 못 함
- (c): +로 판단
1 nearest-neighbor
- k를 1로 고정하고, 각 각의 데이터에 대해서 가까운 영역을 나눈 것을 Voronoi Diagram이라고 한다.

Nearest Neighbor Classification
- 두 점 사이의 거리를 계산할 수 있어야 한다.
- Euclidean distance: d(p,q) = $\sqrt{\sum_{i}(p_i - q_i)^2}$
- 가장 가까운 이웃들 리스트로 클래스 결정
- 다수결로 결정 -> 개수만 생각
- 거리까지 감안해서 투표 -> weight factor, w=$\frac{1}{d^2}$
- Scaling isuues
- attribute의 스케일이 다를 때, euclidean distance를 구하면 문제가 생길 수 있음
- ex) attribute1은 1~10 단위인데, attribute2는 10000~100000 단위이면 제곱할 때, 값이 너무 큼
- Euclidean measure을 사용할 때 문제:
- 높은 차원의 데이터 (차원의 저주) -> attribute가 많으면 거리가 멀어도 판단하기 힘듦
- k-NN classifiers are lazy learners 정리
- 모델을 만들지 않음
- 새로운 데이터를 트레이닝 셋에 있는 데이터들과 각각 거리 비교
- 비용이 비싸다.
- decision tree induction이나 rule-based system 같은 eager learners와 다르다
Bayes Classifier
- lazy learner
- 분류 문제를 해결하기 위한 확률적 프레임워크
- 조건부 확률: P(C|A)=$\frac{P(A∩C)}{P(A)}$
- Bayes theorem: P(C|A)=$\frac{P(A|C)P(C)}{P(A)}$
- 2019/09/30 - [Probability and statistics] - Bayesian Decision Theory

<- 분자만 계산하면 됨
데이터로부터 어떻게 확률을 어떻게 추정할까?

- continuous attributes는 어떻게 확률 계산할까?
- Discretize the range into bins(범위 분할)
- Two-way split: (A<v) or (A>v)
- 확률 밀도 추정 방법:
- attribute가 정규분포(normal distribution)를 따른다고 가정하자
- 일단 확률 분포를 알게 되면 조건부 확률 P(A|C)를 추정하는 데 사용할 수 있다.


Naive Bayes Classifier 예제
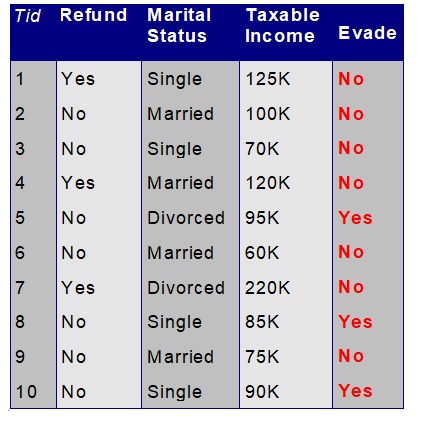

- P(X|Class=No): 조건이 X일 때, 클래스가 no일 확률
- P(X|Class=Yes)를 구할 때, 일부 확률에서 0이 나오는 경우가 있음 ex) P(Married|Class=Yes)
- Probability estimation:
- 분모에 특정 값을 더해 0이 되지 않도록 만든다
- m은 적절히 주어지는 것
- Probability estimation:
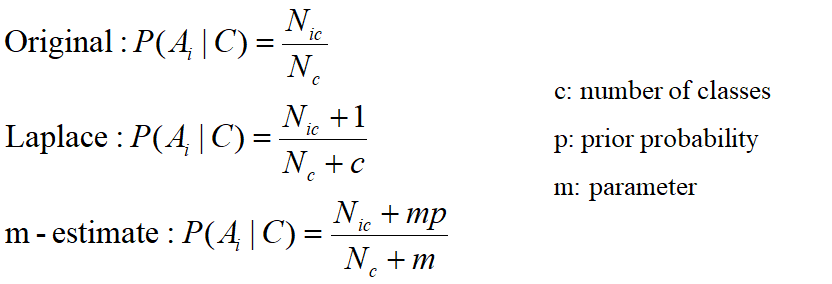
- Naive Bayes 요약
- noise가 있어도 강력
- 없는 값들은 무시하면 됨
- 상관없는 attributes가 섞여있어도 강력 ex) 이름
- 모든 attributes가 독립이라고 가정 (아니더라도)
Neural Network이란?
- 딥러닝 기술
- 참고
- A neural network: 컴퓨터가 관측 데이터를 학습할 수 있도록 생물학적 뉴런 구조를 모방한 패러다임
- a network of connected neurons
- Neuron

ANN(Artificial neural networks)의 일반적인 구조
- input layer은 뉴런 아님 (나머지 layer은 뉴런)

Neural Network Output Format
- 출력 값의 범위는 [0,1]
- 출력 값은 categorial value로 변환된다.
- eg) promotion = yes or no
- two output layer nodes, (node1, node2)
- Yes=(1,0), No=(0,1)
- (0.9, 0.2)는 yes 의미
- 만약 (0.2,0.3) 이런 식으로 나오면 잘못 나온 것!
- One output layer node
- Yes=1, no=0
- 0.8은 yes 의미
- 0.45 이렇게 어중간하게 값 나오면 잘못 나온 것!
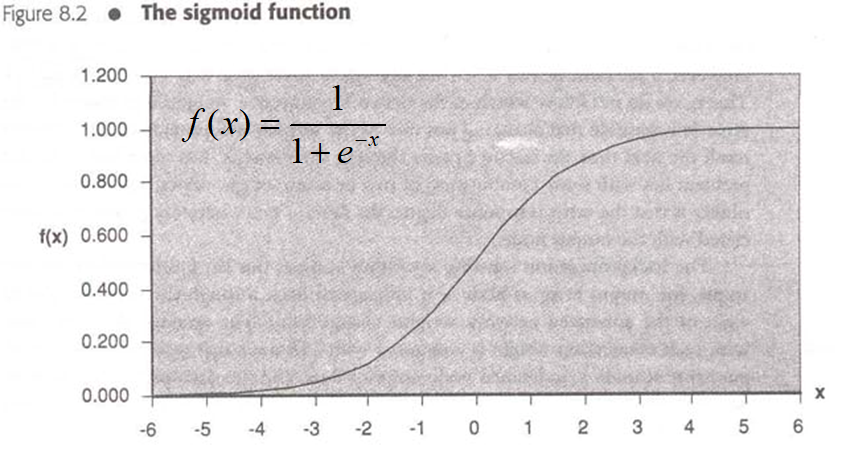
The sigmoid function
- activation function
- 평가 함수 기준: 출력 값은 반드시 정수 범위 [0,1] 이어야 한다.
A Neuron

- 뉴런 여러 개 연결해서 network 구성
- :Multilayered Neural Network -> [input layer / hidden layer / output layer]로 구성됨
- input layer은 뉴런 아님

- 각각의 hidden layer에 모든 input이 다 들어옴
- output layer도 마찬가지로 각각에 모든 hidden layer 출력이 다 들어옴
- layer마다, 노드마다 각각 bias가 다름
- T: 우리가 원하는 결과, O: 우리 모델이 계산한 결과로써 출력
- T와 O가 비슷해지도록 weight와 bias 값을 조절하면서 training
- 왜 weight와 bias를 둘 다 사용하는가?
- weight는 sigmoid 그래프의 모양을 가파르거나 완만하게 만들고
- bias는 sigmoid 그래프를 좌우로 움직인다
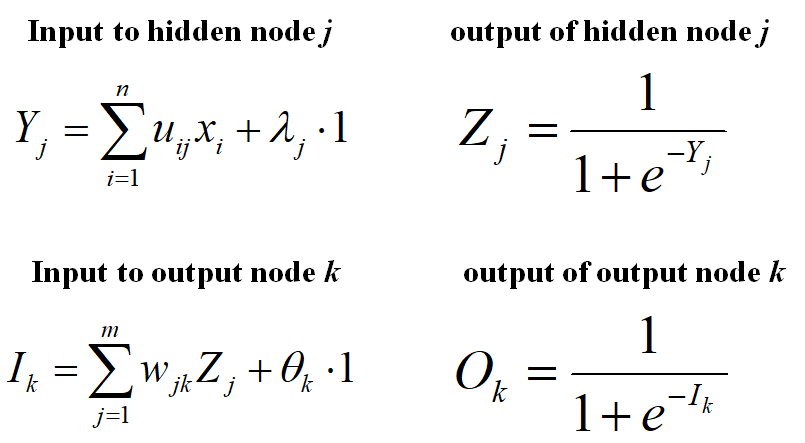

- E 값이 0에 수렴한다는 것은 T와 O가 거의 일치하다는 것

E를 최소화하도록 각 가중치들을 조정하며 학습시킴
ㅇ
반응형
'Data Analysis > Data Mining' 카테고리의 다른 글
'Data Analysis/Data Mining' Related Articles
more




Comments