
Recent Posts
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 겨울 부산
- mp4fpsmod
- kotlin
- table not found
- terminal
- pytest
- 자원부족
- 오블완
- python
- Value too long for column
- 코루틴 컨텍스트
- tolerated
- 티스토리챌린지
- PytestPluginManager
- 코루틴 빌더
- JanusWebRTCServer
- VARCHAR (1)
- Spring Batch
- 깡돼후
- taint
- preemption #
- 달인막창
- vfr video
- k8s #kubernetes #쿠버네티스
- 개성국밥
- JanusWebRTCGateway
- 헥사고날아키텍처 #육각형아키텍처 #유스케이스
- JanusGateway
- PersistenceContext
- JanusWebRTC
Archives
너와 나의 스토리
[Data Mining] Ch4. Classification: Basic concepts, Decision trees, and Model evaluation (1) 본문
Data Analysis/Data Mining
[Data Mining] Ch4. Classification: Basic concepts, Decision trees, and Model evaluation (1)
노는게제일좋아! 2020. 4. 4. 15:02반응형
* 참고 - 2019/08/15 - [Machine learning] - [ML] Decision Tree - classification / regression
Classification 정의
- 목적: 이전에 보지 못했던 데이터들을 최대한 정확히 클래스별로 분류하는 것
- 이런 분류 작업을 위해서 model이 필요
- model을 만들기 위해서는 training set이 필요하다.
- 모델의 정확도를 측정하기 위해서는 test set이 필요하다
- training set과 test set은 같으면 안 된다.
- 학습(learning) - supervised learning / unsupervised learning
- supervised learning: 알고리즘에 주입하는 훈련 데이터에 레이블(label)이라는 답이 포함됨.
- classification은 전형적인 지도 학습(supervised learning)이다. ex) 스팸 필터
- class label이 포함된 test set으로 분류 모델 학습시킴
- 데이터를 분류하는 모델을 생성 (학습 알고리즘)
- Decision Tree
- Deep Neural Network (Deep Learning)
- Bayesian Classifier
- Genetic Algorithm
- Support Vector Machine 등등
- 모델을 사용
- 분류 label을 모르는 새 데이터에 대해서 분류 label을 예측
- 분류기 성능 측정을 위해
- test data 사용 (training data와 달라야 함)
- Precision, Recall -> 성능 측정 지표
- 즉,
- 분류가 된(class label이 있는) 데이터를 훈련 데이터로 사용 -> supervised learning
- 학습된 모델을 사용해 분류 label을 모르는 데이터로 분류 label 예측
- 밑에 그림 보면, test set이 들어오면 class를 예측함 (실제로는 class 정보 가지고 있음)
- 이걸로 precision, recall 계산

Examples of Classification Task
- 종양 세포가 양성인지 악성인지(암인지 아닌지) 예측
- 신용 카드 내역을 보고 합당한 거래인지 사기거래인지 분류
- 뉴스 기사를 보고 금융, 날씨, 예능, 스포츠 등 분야를 분류
Classification Techniques
- Decision Tree based Methods - 참고
- Rule-based Methods
- Memory based reasoning
- Neural Networks - 참고
- Naive Bayes and Bayesian Belief Networks - 참고
- Support Vector Machines
Decision Tree
- 예제 1:
- 고객의 정보를 토대로 컴퓨터를 살만한 사람인지 판단
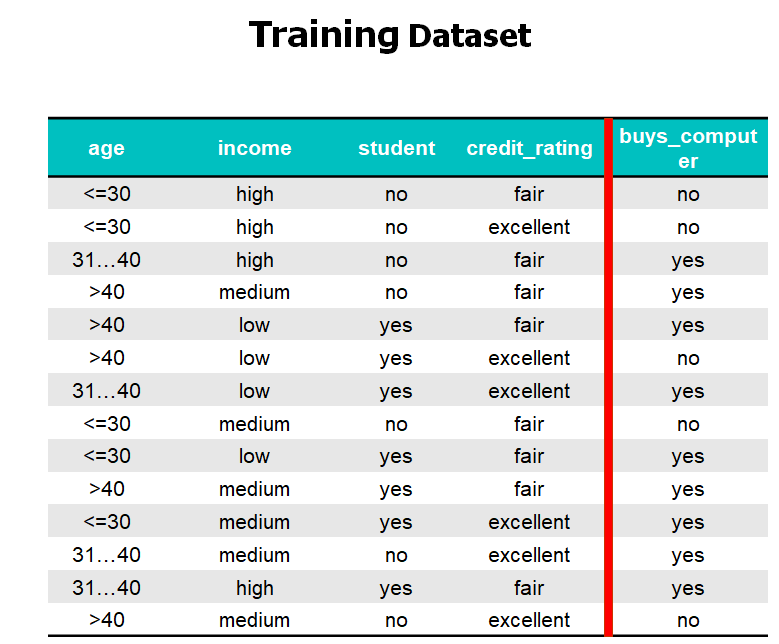
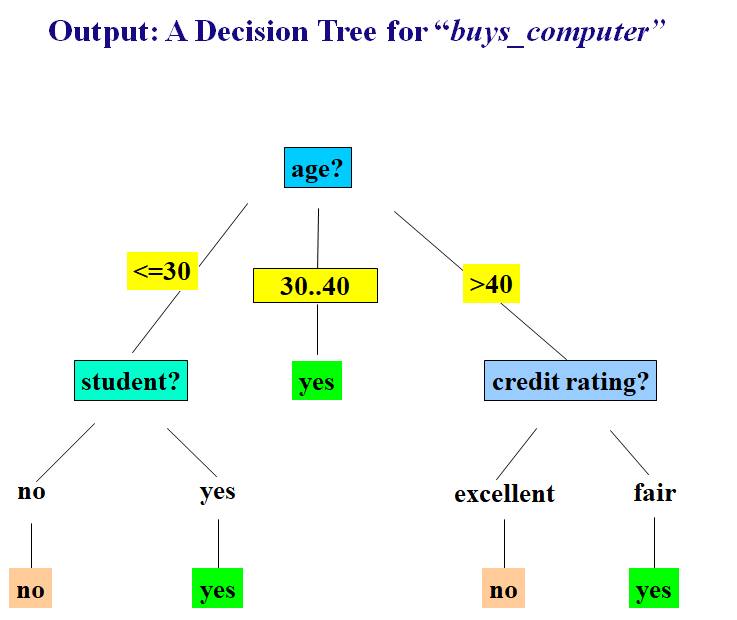
- 예제 2:
- 트레이닝 데이터에 따라 decision tree(모델)가 달라짐

*Decision tree induction algorithm으로 ID3와 C4.5를 주로 배우게 될 것
Tree Induction
- 트리를 어떻게 만들까?
- Greedy strategy
- 특정 기준을 최적화하는 어떤 attribute에 근거하여 records를 쪼갠다.
- Issues
- records를 어떻게 split 할 것인지 결정
- attribute를 어떤 조건들로 나눌 것인가.
- 어떻게 최적의 split을 결정할 것인가.
- 언제 splitting을 멈출지 결정
- records를 어떻게 split 할 것인지 결정
어떻게 test condition을 지정할까?
- attribute type에 따라
- Nominal
- Ordinal
- Continuous
- 분기의 개수에 따라 (=자식 노드의 개수)
- 2-way split
- Multi-way split
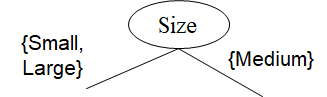
Splitting based on nominal attributes
- Multi-way split: 구별되는 값만큼 많은 partitions 사용

- Binary split: 두 개의 서브셋으로 값들을 나눔. 최적의 partitioning 찾아야 함.
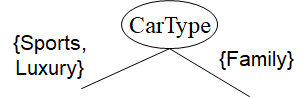
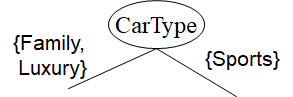
Splitting based on continuous attributes
- 연속 attribute가 가지는 값의 개수는 무한대 -> 모든 경우에 대해 분기할 수 없음
- Discretization: an ordinal categorical attribute 형태로 discretization 필요
- static - 처음에 discretize 한 번 함
- dynamic - equal interval bucketing, equal frequency bucketing (percentiles), clustering으로 구간 발견 가능
- Binary Decision: (A<v) or (A≥v)
- 모든 가능한 splits을 고려해 최적의 cut을 찾음
- 더 많은 연산이 필요할 수도 있다.

어떻게 최적의 split을 결정할까?
- split 전 데이터: [10 records of class 0, 10 records of class 1]
- 다음 중 어떤 test condition이 최적인가?

- Greedy approach:
- homogeneous(unified)하게 class가 분포되어 있는 노드가 선호됨 ( 하나의 클래스에 몰려있는 노드)
- 노드의 impurity(불순도) 측정 필요
- 좋은 케이스: 하나의 클래스로 몰려 있음 -> 불순도(impurity)가 낮고 순도(purity)가 높다

Node impurity 측정
- Gini Index
- Entropy
- Misclassification error
Test attribute를 선택하는 기준
- impurity 기준으로 노드에 대응되는 attribute를 선택
- attribute가 training data를 child nodes로 분배할 때, impurity가 최대한 낮아지게 분류할 수 있는 attribute를 선택
- Information Gain
- Entropy 사용
- Gain Ratio
- Information Gain의 단점을 수정
- Gini Index
- 이것도 impurity를 기준으로 나누지만 IG와 수식이 다름
Entropy
- Entropy: 확률 변수의 정보량
- impurity를 측정하는 지표
- entropy가 낮으면 impurity가 낮음
- 정보의 내용(content)/불확실성(uncertainty)을 포착하기 위한 개념
- 최적 코드를 사용해서 전송한 메시지의 평균 길이
- impurity를 측정하는 지표
- 확률 변수 x의 엔트로피
- H(x) = - $\sum_{x∈X}p(x)\log_2p(x)$
- 엔트로피의 성질
- H(x)≥0
- 메시지의 길이가 길어지면 엔트로피는 증가한다.
- 예
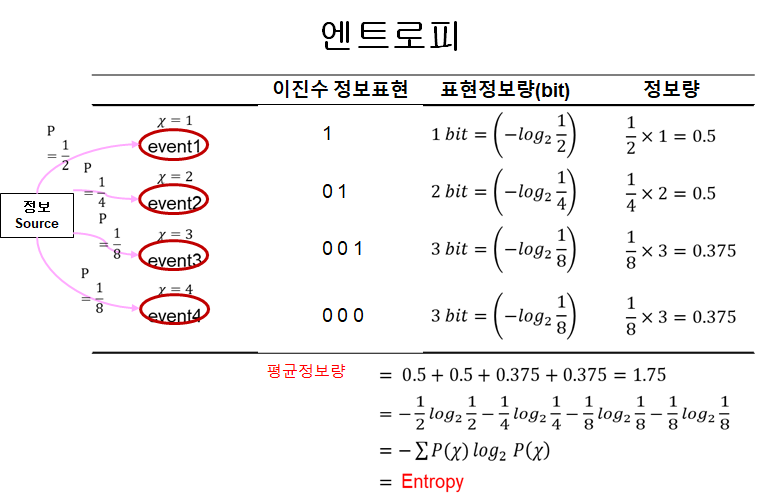
- 어떤 source에서 4가지 event가 발생한다.
- 각 event는 p확률로 발생한다. 즉, 8번의 event가 발생했다면, event1 - 4번/event2 - 2번/event3 - 1번/event4 - 1번 발생
- 이진수 정보표현:
- 각 비트가 event 언제 발생했는지 나타낸 것
- 예를 들어, event1은 event1때 이벤트 발생한 거니까 $1_{(2)}$
- event4는 event1, event2, event3에서 이벤트 발생하지 않은 거니까 $000_{(2)}$
Entropy의 의미 - Binary label 케이스
- 집합 1: P={Y lable 70%, N lable 30%}이 있을 때, 이 집합은 불순도가 높은가?
- Random sample하여 Y가 선택되는 event1의 확률
- p = $\frac{70}{100}$ = 0.7
- Random sample하여 Y가 선택되는 event2의 확률
- q = 1- p = $\frac{30}{100}$ = 0.3
- 집합 P의 Entropy
- H(P) = -$p\log_2p-(1-p)\log_2(1-p)$
- = -0.7·$log_20.7 - 0.3·\log_20.3$ = 0.8813

- 즉, 비율이 반반(균등하게) 분포할 때, 불순도가 가장 높음
Information Gain
- Information Gain = 부모 노드의 Entropy - 자식 노드들의 총 Entropy = H(P) - H(C)
- 부모노드 P의 Entropy (고정)
- p = $\frac{number of Y}{total number of data}$, q = 1-p = $\frac{number of N}{total number of data}$
- H(P) = -$p\log_2p-q\log_2q$
- IG가 크다는 것은 부모 노드의 데이터의 불순도 보다
- 자식 노드의 데이터의 불순도가 더 작아졌다는 것을 의미
- 자식 노드의 데이터의 순도가 더 크다는 것을 의미
- 모든 attribute에 대해서 각각 Information Gain을 구하고
- Test attribute를 선택
- IG가 가장 큰 attribute를 선택하면 자식 노드의 순도가 가장 커질 것이다.
반응형
'Data Analysis > Data Mining' 카테고리의 다른 글
| [Data Mining] Ch4. Classification: Basic concepts, Decision trees, and Model evaluation (3) (0) | 2020.04.15 |
|---|---|
| [Data Mining] Ch4. Classification: Basic concepts, Decision trees, and Model evaluation (2) (0) | 2020.04.07 |
| [Data Mining] CH3. Data Exploration (2) (0) | 2020.03.31 |
| [Data Mining] CH3. Data Exploration (1) (2) | 2020.03.25 |
| [Data Mining] CH2. Data (2) (0) | 2020.03.23 |
'Data Analysis/Data Mining' Related Articles
more




Comments