
Recent Posts
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- tolerated
- 코루틴 컨텍스트
- 티스토리챌린지
- python
- pytest
- PersistenceContext
- Spring Batch
- 개성국밥
- mp4fpsmod
- 코루틴 빌더
- PytestPluginManager
- 달인막창
- JanusWebRTC
- VARCHAR (1)
- 겨울 부산
- preemption #
- 자원부족
- table not found
- JanusGateway
- JanusWebRTCGateway
- Value too long for column
- JanusWebRTCServer
- terminal
- 헥사고날아키텍처 #육각형아키텍처 #유스케이스
- 깡돼후
- 오블완
- kotlin
- k8s #kubernetes #쿠버네티스
- vfr video
- taint
Archives
너와 나의 스토리
[Data Mining] CH3. Data Exploration (1) 본문
반응형
Data exploration이란?
- 데이터 특성을 더 잘 이해하기 위한 예비 조사
- 어떤 패턴이 있는지 찾아야(데이터 탐색) 데이터 마이닝 가능.
- 데이터 탐색의 주요 동기:
- 전처리나 분석을 위한 옳은 도구를 선택하는데 도움을 줌
- 패턴을 인지하는 인간의 능력을 활용
- 인간은 데이터 분석 도구로 탐지되지 않는 패턴도 인지 가능
Techniques used in data exploration
- EDA(Exploratory Data Analysis): Tukey가 정의
- 시각화에 초점을 맞춤
- Clustering and anomaly detection은 exploratory techniques으로 보일 수 있다.
- 데이터 마이닝을 하는 사람들은, Clustering and anomaly detection을 탐색이라고 생각하지 않는다.
- 데이터 탐색에 대해 우리는 다음에 집중할 것:
- Summary statistics
- Visualization
- Online Analytical Processing (OLAP)
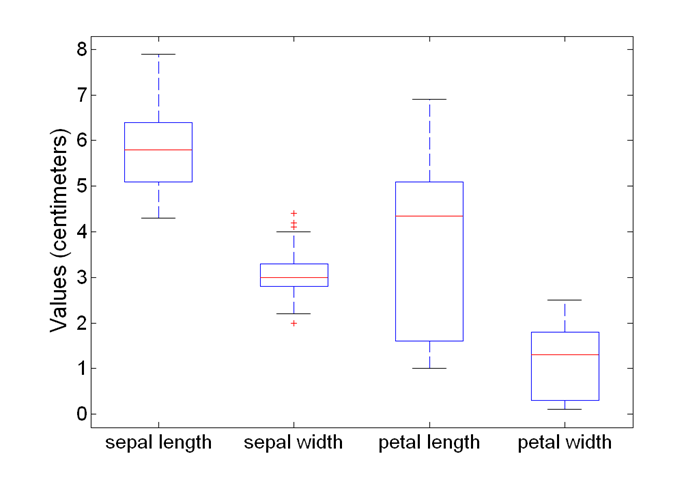
Iris sample data set
- 많은 탐색 데이터 기술을 Iris plant 데이터 셋으로 보여줌
- 데이터 셋: http://www.ics.uci.edu/~mlearn/MLRepository.html
- 세 가지 꽃 유형 (classes):
- Setosa
- Virginica
- Versicolour
- 네 가지 (non-class) attributes:
- Sepal width and length
- Petal width and length
Summary statistics
- 데이터들의 요약 정보 보기 -> 통계적인 기법을 많이 사용
- Summarized properties: frequency, location, spread
- Examples:
- location - mean
- spread - standard deviation
- Examples:
Frequency and mode
- attribute 값의 빈도는 데이터 셋에서 그 값이 발견된 비율
- attrbute의 mode(최빈값)은 가장 빈도가 높은 attribute 값
- frequency와 mode의 개념은 주로 categorical data에서 사용된다.
Percentiles(백분위)
- attribute의 값이 연속일 때 percentile 개념이 유용
- Ordinal attribute에도 사용될 수 있는데, attribute의 개수가 굉장히 많을 때 사용됨
- Ordinal 또는 연속적인 attribute x와 [0,100] 사이의 수인 p가 주어질 때, p번째 percentile은 x의 값 Xp으로 Xp보다 작은 x 값이 관찰된 p%이다.
- ex) 50번째 percentile은 값 X50%보다 작은 모든 x의 값의 비율이 50%이다.
- ex) 나이 - 0~120살 정도 산다고 할 때, 45살 미만의 사람들이 우리나라 국민의 절반을 차지한다고 하자
- 나이라는 attribute의 50% percentile은 45세가 된다.
Measures of Location: Mean and Median
- 평균은 점들의 위치를 측정할 때 가장 많이 사용하는 것이지만, 이상치에 굉장히 민감하다.
- 따라서, 중앙값(median) 또는 trimmed mean(다듬은 평균)을 주로 사용한다.

Measures of spread: Range and Variance
- Range는 max와 min 사이
- 분산(variance)과 표준 편차(standard deviation)는 점들의 집합이 퍼져있는 정도를 측정할 때 가장 많이 사용되는 것이다.
- 분산도 이상치에 민감하기 때문에 주로 다른 측정을 사용한다.
- 이상치로 엄청 큰 값이 있을 때 제곱을 하면 너무 값이 커지니까 제곱을 안 하는 방법을 사용
Visualization
- 시각화는 데이터를 시각적 표형식(tabular format)으로 변환한 것 -> 데이터의 특성과 데이터 아이템 또는 attribute 사이의 관계가 쉽게 분석되거나 보고되기 쉽도록.
- 데이터의 시각화는 가장 강력한 데이터 탐색 기술 중 하나이다.
Representation
- 정보를 시각적인 형식으로 매핑한 것
- 데이터 객체, 그것의 attributes, 데이터 객체 사이의 관계를 점, 선, 모양, 색 같은 것들로 그래프 요소로 변환
- ex:
- 객체들은 주로 점들로 표현된다.
- 그들의 attribute 값들은 점들의 위치나 점들의 특성으로 표현된다 (e.g. color, size, and shape)
- 만약 위치를 사용하면, 점들의 관계(i.e. 그룹을 형성하는지, 어떤 점이 이상치인지)를 쉽게 인식할 수 있다.
Arrangement
- 배열(arrangement)은 디스플레이 내에 시각적 요소를 배치하는 것이다.
- 데이터를 더 쉽게 이해할 수 있게 함.
- ex:
Selection
- 선택(selection)은 데이터의 객체나 attributes가 많을 때 이 사이즈를 줄이기 위해서 선택함.
- 선택은 attribute의 subset을 고르는 것을 포함한다:
- 보통 차원을 2~3개로 줄임
- 대안으로 pairs of attributes를 고려 -> attribute끼리 쌍을 지어, 2개씩 보기
- 선택의 objects의 subset을 고르는 것을 포함한다: 샘플링
- 랜덤 샘플링은 빈도가 높은 영역의 점들만 골라질 수도 있음 -> 고려해야할 점
Visualization techniques: Histograms
- 1차원 히스토그램:
- 2차원 히스토그램:
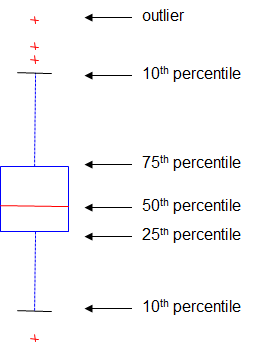
Visualization techniques: Box plots
- 10%이하의 비율을 가지는 점들을 이상치로 판단
- 50th 값 -> 중간값 (평균 아님)
Visualization Techniques: Scatter Plots
- 보통 2차원을 사용 -> 2개의 attributes만 선택해서 데이터의 포인터를 보여줌(값의 분포)
- 예시: 대각선을 기준으로 대칭됨
Visualization Techniques: Contour Plots
- 연속적인 attributes에서 주로 사용됨
- 평면을 비슷한 값의 영역으로 분할
- 등고선(contour lines)은 동일한 값을 가지는 점들을 연결하는 영역의 경계를 형성한다
- 예시:
Visualization Techniques: Matrix Plots
- 데이터 matrix를 그릴 수 있는 기술
- 클래스에 따라 객체를 분류할 때 유용
- 일반적으로 하나의 attribute가 plot을 지배하지 못하도록 attributes를 표준화(normalize)한다.
- 유사성이나 거리 matrices의 plots은 객체들의 관계를 시각화할 때 유용하다.
- 예시1:
- 좌측 상단을 보면, 파란색이 많다 -> setosa에는 sepal length가 작은 데이터가 많다는 것
- 좌측 하단을 보면, 붉은색이 많다 -> virginica에는 sepal length가 큰 데이터가 많다는 것
- 예시2:
- 각 attribute끼리의 상관관계를 보여줌
- setosa와 setosa는 같은 것이니까 상관관계가 높음 -> 붉은색
Visualization Techniques: Parallel Coordinates
- 고차원 데이터에서 attribute 값들 보여줄 때 사용
- 예시: 한 줄이 한 개의 데이터를 나타냄
Other visualization techniques
- Star Plots
- 각 축(선)이 attribute가 됨
- Chernoff Faces
- 눈, 코, 입 크기를 attribute에 대입
* OLAP -> 중요 ( 다음에 정리 )
반응형
'Data Analysis > Data Mining' 카테고리의 다른 글
| [Data Mining] Ch4. Classification: Basic concepts, Decision trees, and Model evaluation (2) (0) | 2020.04.07 |
|---|---|
| [Data Mining] Ch4. Classification: Basic concepts, Decision trees, and Model evaluation (1) (0) | 2020.04.04 |
| [Data Mining] CH3. Data Exploration (2) (0) | 2020.03.31 |
| [Data Mining] CH2. Data (2) (0) | 2020.03.23 |
| [Data Mining] CH2. Data (1) (2) | 2020.03.21 |
'Data Analysis/Data Mining' Related Articles
more



