
Recent Posts
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- k8s #kubernetes #쿠버네티스
- pytest
- VARCHAR (1)
- Spring Batch
- 코루틴 컨텍스트
- table not found
- vfr video
- JanusWebRTC
- PersistenceContext
- 자원부족
- 헥사고날아키텍처 #육각형아키텍처 #유스케이스
- terminal
- kotlin
- preemption #
- python
- tolerated
- JanusGateway
- taint
- 겨울 부산
- JanusWebRTCServer
- mp4fpsmod
- Value too long for column
- PytestPluginManager
- 개성국밥
- 코루틴 빌더
- JanusWebRTCGateway
- 달인막창
- 깡돼후
- 오블완
- 티스토리챌린지
Archives
너와 나의 스토리
[Data Mining] CH2. Data (1) 본문
반응형
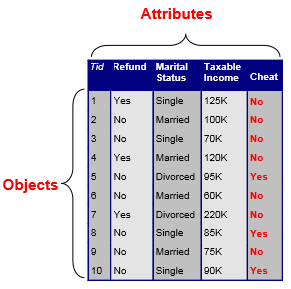
Data란?
- 데이터 objects와 그들의 attributes의 모음
- attributes: 데이터를 설명하는 특성.
- ex) 사람의 눈 색
- attribute = variable, field, characteristic, feature
- 여러 개의 attribute가 하나의 object를 설명함
Attribute Values
- Attribute values는 attribute에 할당된 숫자나 기호이다.
- attributes와 attribute values의 차이
- 같은 attibute는 다른 attribute values와 매핑될 수 있다.
- ex) 키는 feet나 meters로 측정될 수 있음
- 키 - attribute, 측정 단위 - attribute value
- 다른 attributes는 같은 value들의 집합으로 매핑될 수 있다.
- ex) 주민등록번호나 나이의 attribute values는 정수이다.
- 같은 attibute는 다른 attribute values와 매핑될 수 있다.
Types of Attributes
- Nominal
- categorical type(범주형)이라고도 함
- 순서가 없다
- 숫자일 수도, 문자일 수도 있다
- Ordinal
- 주로 숫자
- 데이터와 데이터 사이에 순서 관계
- ex) rankings, grades, height in {tall, meduim, short}
- Interval
- 구간의 값이 정해진 것
- ex) 달력 날짜, 섭씨 or 절대 온다
- Ratio
- 절대 기준이 있는 것
- ex) Kelvin, 길이, 시간, 개수 온도
Properties of Attribute Values
- Attribute의 type은 다음 중 어떤 속성을 소유하느냐에 따라 다르다:
- Distinctness: = ≠ ( 같다 or 다르다 )
- Order: < > ( 크다 or 작다 -> 순서 )
- Addition: + - ex) 온도
- Multiplication: * / ( 비율 ex) 2배, 3배이다 )
- Nominal attribute: distinctness
- Ordinal attribute: distinctness & order
- Interval attribute: distinctness & order & addition
- Ration attribute: all 4 properties

데이터 변환할 때
- Nominal
- 순서 관계가 없기 때문에 아무 값이나 할당 가능
- Ordinal
- 순서 관계 유지되야함
- Interval
- 구간을 가지고 변환해야 함
- Ratio
- 비율을 가지고 변환 (2배로 증가시키기)
Types of data sets
- Record
- Data Matrix (표현식)
- Document Data
- 사람들의 frequency를 data matrix 형태로 표현
- Transaction Data
- Graph
- World Wide Web
- Molecular Structures
- Ordered
- Spatial Data
- 전, 후, 좌, 우, 위, 아래
- Temporal Data
- Sequential Data
- Genetic Sequence Data
- 유전자들이 연결되어 있다
- Spatial Data
구조화된 데이터의 중요한 특성
- Dimensionality
- Curse of Dimensionality (차원의 저주)
- Sparsity (희소성)
- Only presence counts
- 데이터들이 공간적으로 띄엄띄엄 존재
- Resolution (해상도)
- 규모에 따라서 데이터가 나타나는 패턴이 달라짐
Data Matrix
- Record를 Data Matrix로 표현할 수 있음
- 모든 데이터가 똑같은 attribute로 구성되어 있어야 함
- 데이터 객체가 같은 고정된 numeric attributes의 집합을 가진다면, 데이터 객체는 각 attribute가 고유한 속성을 나타내는 attribute들을 대응한 다차원의 점으로써 생각될 수 있다.
- = Data Matrix로 표현될 수 있는 데이터들은 attribute가 각 차원을 구성하고, 각 차원들을 대응하면 다차원 공간에 하나의 점으로 간주할 수 있다.
- 각 데이터 집합은 m by n 행렬로 나타낼 수 있다.
Document Data
- 문장들이 들어있는 데이터
- 이 데이터를 이해하려면 문장을 이해해야 하는데 -> 사실상 불가능
- 이를 좀 더 쉽게 하기 위해
- 'term(단어)'를 가지고 문서를 표현함 (각 document는 'term' 벡터가 됨)
- 각 term은 벡터의 구성 요소가 됨
- 각 구성 요소의 값은 대응되는 단어가 문서에서 나타난 횟수이다

Transaction Data
- 물건 사고 나온 영수증 보면,
- 각 record (transaction)는 물품들의 집합을 포함함

Graph Data
- 데이터와 데이터 사이에 연결 선이 있는 그래프
- Directive, Undirective graph 둘 다 될 수 있음

Chemical Data
- 이런 화학 구조식에서 원소가 데이터고, 각 데이터를 연결하는 선이 있음

Ordered Data
- 순서가 있는 데이터
- Transaction에 있는 데이터들의 시퀀스도 일종의 ordered data이다.
- ex) 같은 시간에 a, b라는 아이템을 사고 일정 시간이 지난 후 d라는 물건을 사고, 그 후 c, d를 샀다

- Genomic sequence data

- Spatio-Temporal Data
- 공간적으로 데이터가 퍼져있고, 시간에 따라 변화함

Data Quality
- 양질의 데이터인지, 의미 있는 데이터인지
- 어떤 종류의 데이터 품질 문제가 있는가?
- 어떻게 데이터 문제를 탐지할 수 있는가?
- 이러한 문제에 대해 우리가 뭘 할 수 있는가?
- Examples of data quality problems:
- Noise and outliers
- missing values
- duplicate data
Noise
- 원래 데이터에 들어온 잡음
Outliers
- 대다수의 데이터와 떨어져 있는 소수의 데이터들을 의미
Missing Values
- 어떤 attribute에 이유는 모르지만 값이 안 들어온 상황
- 값이 안 들어온 2가지 경우:
- 값이 있긴 있는데 값을 구하지 못한 경우
- ex) 대상이 되는 사람이 정보를 주기 거부하는 경우
- 값이 아예 존재하지 않는 경우
- ex) 초등학생의 연수입 -> 존재 x
- 값이 있긴 있는데 값을 구하지 못한 경우
- missing values 다루기
- missing value가 있는 데이터 객체 없애버리기
- missing value를 추정해서 집어넣기
- 분석할 때 missing value를 무시
- 가능한 값으로 채워 넣기
Duplicate Data
- 똑같은 데이터가 여러 개 있는 것
- 주로 발생하는 상황: 작은 데이터가 흩어져 있고 이를 합치려고 할 때 자주 발생
- 중복된 것 없애기
Data Preprocessing (데이터 전처리)
- Aggregation
- 두 개 이상의 attribute를 한 개의 attribute로 묶는 것이 아니라,
- 어떤 attribute의 값에 대해 여러 개의 object를 1개의 값으로 변환하는 것
- ex) 각 데이터가 나이를 가지고 있을 때, 이 나이 값을 평균 낸다면 한 개의 값으로 바뀜
- 목적
- Data reduction -> 데이터 사이지 줄이기
- Change of sacle
- More "stable" data
- 노이즈를 제거함으로써
Sampling
- 데이터가 굉장히 많은 경우에 그중에서 일부를 랜덤 하게 추출함으로써 데이터의 사이즈를 줄이는 것
- 사용하는 이유:
- 데이터의 사이즈가 클 경우, 이를 다 처리하는데 너무 오래 걸리고 expensive 함
- 이렇게 해도 큰 오류가 없이 유의미한 결과를 얻을 수 있기 때문
- Types of Sampling
- Simple Random Sampling
- 각 항목이 같은 확률을 가지고 뽑힘
- Sampling without replacement
- 랜덤으로 뽑는데, 방금 샘플링한 것을 모집단에 다시 넣지 않음
- Sampling replacement
- 랜덤으로 뽑고, 방금 샘플링한 것을 다시 모집단에 넣음
- 방금 뽑은 것을 다음에 다시 뽑을 수도 있음
- Stratified sampling
- 데이터의 분포를 보고, 데이터의 분포의 특성에 맞게 샘플링
- 데이터가 밀도가 높은 곳에서는 많이 뽑고 하는 식
- or 데이터 밀도가 낮은 곳에서 더 많이 뽑을 수도 있음
- Simple Random Sampling
- Sample Size
- 10개의 그룹에서 각각 적어도 하나씩 데이터가 뽑히려면 얼마나 뽑아야 하나

Curse of Dimensionality
- 차원이 증가할 때, 데이터가 차지하는 공간에서는 데이터가 점점 희박해짐
- -> 모든 데이터가 거의 비슷한 거리에 놓이게 되는 것
- 데이터의 거리를 가지고 similarity를 계산하는데 이런 걸 못 함
- -> clustering, outlier 탐지가 어려워지고, 의미가 사라짐
- attribute가 n개 일 때, 이를 n 차원으로 표현하면 분석한다고 할 때, n이 커질수록 분석하기 어려워지는 것을 차원의 저주라고 함
Dimensionality Reduction
- 목적:
- 차원 저주 현상을 피하기 위해 차원을 축소한다
- 데이터 분석을(Data mining algorithm) 위해 필요한 시간과 메모리를 줄이기 위해
- 시각화하는 것을 쉽게 하기 위해
- 부적절한 feature을 제거
- 방법:
- Principal Component Analysis
- Singular Value Decomposition
- Others: supervised and non-linear techniques
- Principal Component Analysis (주성분 분석)
- 대부분 데이터를 다차원 공간의 한 점으로써 나타내면, 실제 데이터의 분포는 다차원의 부분 공간(subspace)의 특징을 가진다.
- 데이터가 어떤 방향으로 주로 모여 있는지에 대한 측정을 할 수 있음
- ex) 2차원의 데이터에 점들이 있다고 하자. 밑에 그래프를 보면 3시 방향으로 넓게 분포하고 있고 11시 방향으로는 덜 넓게 분포하고 있다. 즉, 3시 방향으로의 variation이 훨씬 크다는 것이므로 이쪽을 주 성분이라고 함.
- variation(변화)가 큰 3시 방향으로 데이터를 매핑해서, 이 쪽에 있는 점들을 표시하면 2차원에 있는 데이터를 1차원의 데이터로 축소할 수 있다.
- covariance matrix 사용함

차원 축소: PCA
- covariance matrix의 eigenvectors를 구함
- 아이젠 벡터가 새로운 공간을 정의
- 밑에 그래프에서는 3시 방향, 11시 방향 두 개의 아이젠 벡터가 나옴
- 아이겐 값이 큰 아이겐 벡터를 선택하면 그것이 주성분 벡터가 돼서, 그쪽 방향으로 차원을 축소함

- 이렇게 차원을 축소하면 데이터 손실은 발생함
- 새로운 attribute가 생김
Feature Subset Selection
- 새로운 attribute를 생성하는 것이 아니라, attributes 중에서 일부 attribute를 선택하는 것
- 중복된 feature
- ex) 제품의 구매 가격과 세금의 양
- 둘 중 하나는 삭제해도 괜찮
- 상관없는 feautre
- ex) 학생의 성적을 예측하는데, 학생의 학번 같은 건 필요 없음
Feature Creation
- 원래 attributes보다 효율적인 데이터 집합에서 중요한 정보를 가져와 새로운 attribute를 만듦
- 3가지 일반적인 방법론:
- Feature Extraction
- domain-specific
- Mapping Data to New Space
- Feature Construction
- combining features
- Feature Extraction
- Mapping Data to a New Space
- 어떤 데이터가 어떤 주기를 가지고 있다면, 거리 도메인의 데이터를 주파수 도메인의 데이터로 변환시킴으로써 데이터의 사이즈를 줄일 수 있다.
- Fourier transform
- Wavelet transform
- Discretization Using Class Labels
- x가 가지는 값의 개수가 무한대이지만 각 구간에 하나의 값을 가지도록 이사를 하면
- 각 attribute가 가지는 서로 다른 값의 개수가 줄어들게 되어 분석하기 좋아짐
- 그렇다면, 어떻게 구간을 나누는가?
- -> Entropy based approach

- Discretization Without Using Class Labels
- x축은 attributes의 값이고 y축은 각 attribute의 특정 값을 가질 때, 어떤 분포를 가지는지 보여줌
- 데이터가 얼마나 많이 모여있는지 빈도를 나타내는 것
- 이때, 어떻게 구간을 나누는가?
- 3가지 방법:
- Equal interval width
- 구간의 길이를 똑같이 둠 -> x가 가진 attribute 값이 4개로 줄어듦
- x가 이 구간 안에 있을 때, 데이터가 몇 개 있는지 카운트
- Equal frequency
- 구간 안에 들어가는 데이터의 개수가 똑같도록 구간을 나눔
- equal interval width보다 분석하는데 더 유의미하다고 볼 수 있음
- but, 시간은 좀 더 걸림
- K-means
- 데이터의 클러스터 사이에 경계를 넣음
- Equal interval width
- 3가지 방법:

Attribute Transformation
- 어떤 attribute 값에 대응되는 다른 attribute 값을 변환하는 것
- 보통 시계열 데이터에서 많이 사용됨
- 시계열 데이터 예: 시간이 지남에 따라서 주가, 기온 등 값이 어떻게 변화하는지 보는 그래프
- 특정 함수를 대입해서 변환

반응형
'Data Analysis > Data Mining' 카테고리의 다른 글
| [Data Mining] Ch4. Classification: Basic concepts, Decision trees, and Model evaluation (2) (0) | 2020.04.07 |
|---|---|
| [Data Mining] Ch4. Classification: Basic concepts, Decision trees, and Model evaluation (1) (0) | 2020.04.04 |
| [Data Mining] CH3. Data Exploration (2) (0) | 2020.03.31 |
| [Data Mining] CH3. Data Exploration (1) (2) | 2020.03.25 |
| [Data Mining] CH2. Data (2) (0) | 2020.03.23 |
'Data Analysis/Data Mining' Related Articles
more




Comments