
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- JanusWebRTCGateway
- table not found
- 코루틴 컨텍스트
- python
- 오블완
- JanusWebRTCServer
- tolerated
- pytest
- taint
- kotlin
- PytestPluginManager
- PersistenceContext
- Value too long for column
- vfr video
- mp4fpsmod
- 헥사고날아키텍처 #육각형아키텍처 #유스케이스
- Spring Batch
- 티스토리챌린지
- 달인막창
- preemption #
- 자원부족
- JanusWebRTC
- 코루틴 빌더
- 겨울 부산
- JanusGateway
- terminal
- 개성국밥
- k8s #kubernetes #쿠버네티스
- VARCHAR (1)
- 깡돼후
목록Data Analysis/Machine learning (52)
너와 나의 스토리
 모두를 위한 딥러닝 - RNN 실습(2)
모두를 위한 딥러닝 - RNN 실습(2)
모두를 위한 딥러닝 ML lab12-2: RNN - Hi Hello Training 강의 정리&코드 전체 코드: https://github.com/hunkim/DeepLearningZeroToAll/blob/master/lab-12-1-hello-rnn.py 1. RNN model 적합한 것 골라 쓰기 2. Data creation idx2char = ['h', 'i', 'e', 'l', 'o'] # Teach hello: hihell -> ihello x_data = [[0, 1, 0, 2, 3, 3]] # hihell x_one_hot = [[[1, 0, 0, 0, 0], # h 0 [0, 1, 0, 0, 0], # i 1 [1, 0, 0, 0, 0], # h 0 [0, 0, 1, 0, 0], # e..
 모두를 위한 딥러닝 - RNN 실습(1)
모두를 위한 딥러닝 - RNN 실습(1)
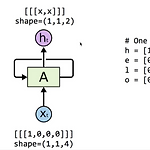
모두를 위한 딥러닝 ML lab12-1: RNN - Basics 강의 정리&코드 전체 코드: https://github.com/hunkim/DeepLearningZeroToAll/blob/master/lab-12-0-rnn_basics.ipynb 1. 데이터 # One hot encoding h = [1, 0, 0, 0] e = [0, 1, 0, 0] l = [0, 0, 1, 0] o = [0, 0, 0, 1] # input dimension -> 4 (0,0,0,0) 입력 데이터의 dimension이 뭐든 상관없이 출력의 dimension은 우리가 설정한 hidden_size를 따름 2. cell 만들기 with tf.variable_scope('one_cell') as scope: hidden_siz..
● sequence-to-sequence network - 주식가격 같은 시계열 데이터를 예측하는 데 유용 - 최근 N일치의 주식각격을 주입하면 네트워크는 하루 앞선 가격을 출력해야 한다. (즉, N-1일 전부터 내일까지 모든 출력을 다 봄) ● sequence-to-vector network - 입력 시퀀스를 네트워크에 주입하고, 마지막을 제외한 모든 출력 무시 - ex) 영화 리뷰에 있는 연속된 단어를 주입하면 네트워크는 감성 점수를 출력 - 인코더(encoder)라고 불림 ● delayed sequence-to-sequence network - 인코더(encoder)라고 불리는 sequence-to-vector network 뒤에 디코더(decoder)라 불리는 vector-to-sequence n..
1.1 머신러닝이란? 머신러닝 정의 - 일반적인 정의: 명시적인 프로그래밍 없이 컴퓨터가 학습하는 능력을 갖추게 하는 연구 분야 - 공학적인 정의: 어떤 작업 T에 대한 컴퓨터 프로그램의 성능을 P로 측정했을 때 경험 E로 인해 성능이 향상됐다면, 이 컴퓨터 프로그램은 작업 T와 성능 측정 P에 대해 경험 E로 학습한 것이다. 정의 - 훈련 세트(training set): 시스템이 학습하는 데 사용하는 샘플 - 훈련 사례(training instance): 각 훈련 데이터 - 데이터 마이닝(data mining): 머신러닝 기술을 적용해서 대용량의 데이터를 분석하면 겉으로는 보이지 않던 패턴을 발견하는 것. ex) 스팸 필터는 스팸 메일과 일반 메일의 샘플을 이용해 스팸 메일 구분법을 배울 수 있는 머신..
 cross-entropy cost function
cross-entropy cost function
cross-entropy : 불확실성의 정도 - SEE(Sum Squared Error)보다 수렴이 빠르다 - classification 문제 / deep learning에서 많이 사용한다. ( regression 문제에서는 SEE 많이 사용) - 대칭적(symmetric)이지 않다. sigmoid function에서는 z가 어느정도 작거나 큰 값일 때, 항상 0이나 1에 가까운 값을 출력하기 때문에, 입력의 변화가 출력에 반영되기 어렵다. 그 결과, 오차 함수의 가중치 매개 변수에 대한 편미분이 0에 가까운 값이되어, 경사 하강법의 학습이 늦어지는 문제가 있다. 그래서 cross-entropy를 이용하여 cost function을 만든다. cross-entropy cost function S(y): 출..
 Approximate entropy(ApEn)
Approximate entropy(ApEn)
Wikipedia 참고 ApEn 통계에서 ApEn(approximate entropy)는 time series 데이터에 대한 규칙성의 양과 변동성의 예측 불가능성을 정량화하는데 사용된다. -> 규칙성의 정도, 불확실성의 정도 시계열에서 반복되는 변동 패턴의 존재는 그러한 패턴이 없는 시계열보다 더 예측 가능하게 한다. ApEn은 유사한 관찰 패턴이 추가로 유사한 관찰에 이어지지 않을 가능성을 반영한다. 많은 반복 패턴을 포함하는 시계열은 상대적으로 작은 ApEn을 가지고, 덜 예측 가능한 프로세스는 더 높은 ApEn을 가진다. ApEn's algorithm Step1. 시계열 형태의 데이터 $u_{1}$, $u_{2}$,...,$u_{n}$. 시간의 균등한 간격으로 측정한 N개의 원시 데이터 값이다. S..
 Keras 함수 / Numpy 함수 정리
Keras 함수 / Numpy 함수 정리
Keras Keras Decumentation참고 ● Sequential - keras.models.Sequential() - Neural Network를 초기화하는데 필요 - model 생성자 ● add - models.add() - sequential로 만든 모델에 특성 넣어줌 ● Dense - keras.layers.Dense(,,,) - input_dim: 입력 뉴런의 수 설정 - init: 가중치 초기화 방법 설정 (uniform / normal) - activation: 활성화 함수 설정 (linear / relu / sigmoid / softmax) - 입력 뉴런과 출력 뉴런을 모두 연결해준다. - 참고 [출처: 데이터 사이언스 스쿨] ● GRU - keras.layers.GRU() - LS..
 NN(Neural Network) - backpropagation
NN(Neural Network) - backpropagation
* '핸즈온 머신러닝' 책의 내용을 기반으로 작성 ● 퍼셉트론(Perceptron) 가장 간단한 인공 신경망 구조 중 하나 TLU(threshold logic unit)라는 조금 다른 형태의 인공 뉴런을 기반으로 한다. 입력과 출력이 어떤 숫자고 각각의 입력 연결은 가중치와 연관되어 있다. 층이 하나뿐인 TLU로 구성된다. ● TLU 간단한 선형 이진 분류 문제에 사용할 수 있다. 입력의 선형 조합을 계산해서 그 결과가 임곗값을 넘어서면 양성 클래스를 출력하고 그렇지 않으면 음성 클래스를 출력한다. 여기에 편향 특성이 더해진다. ● 다층 퍼셉트론(Multi-Layer Perceptron) - MLP 여러 퍼셉트론을 쌓아올려 일부 제약을 줄일 수 있는데, 이런 신경망을 MLP라고 한다. [입력층 하나 + ..